
How to Setup AutoML Time Series
AutoML Time Series is a machine learning approach that automates the process of building, selecting, and tuning models for time-based data. It enables users to perform tasks like forecasting, anomaly detection, and trend analysis without needing deep expertise in data science.
By handling tasks such as feature engineering, model selection, and hyperparameter optimization automatically, AutoML for time series accelerates insights and improves accuracy across industries like finance, retail, manufacturing, and energy.
Project requirement
Before creating an AutoML Time Series object in your Ai workshop project, you need to create a Table Repository object to designate the table that contains the time series data. You have the possibility to rename the table for more convenience. This object will be available for selection in the AutoML Time Series object.
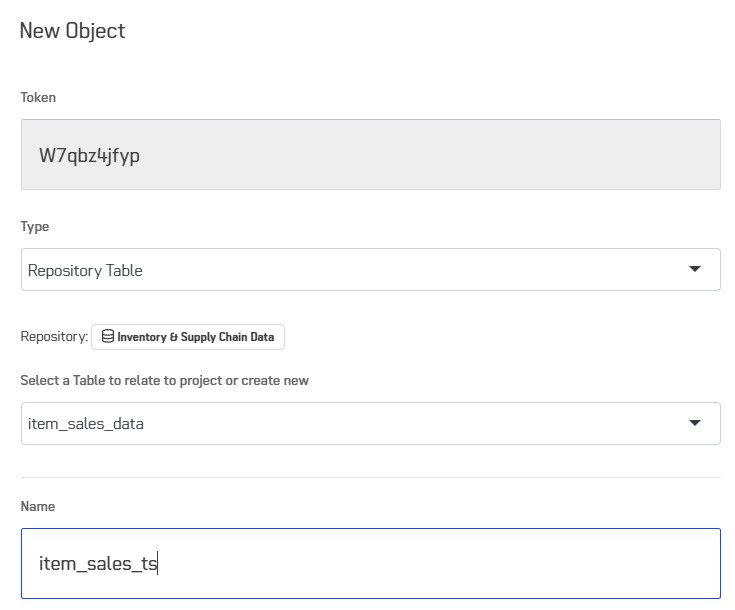
Time series prediction setup
Add a new object in your project with type AI & Machine Learning, and with Development Environment AP AutoML TimeSeries GPU Engine.
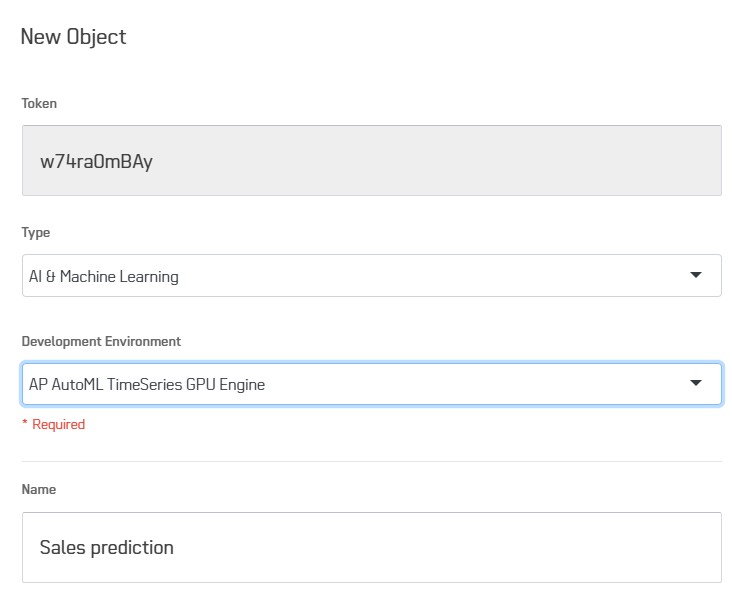
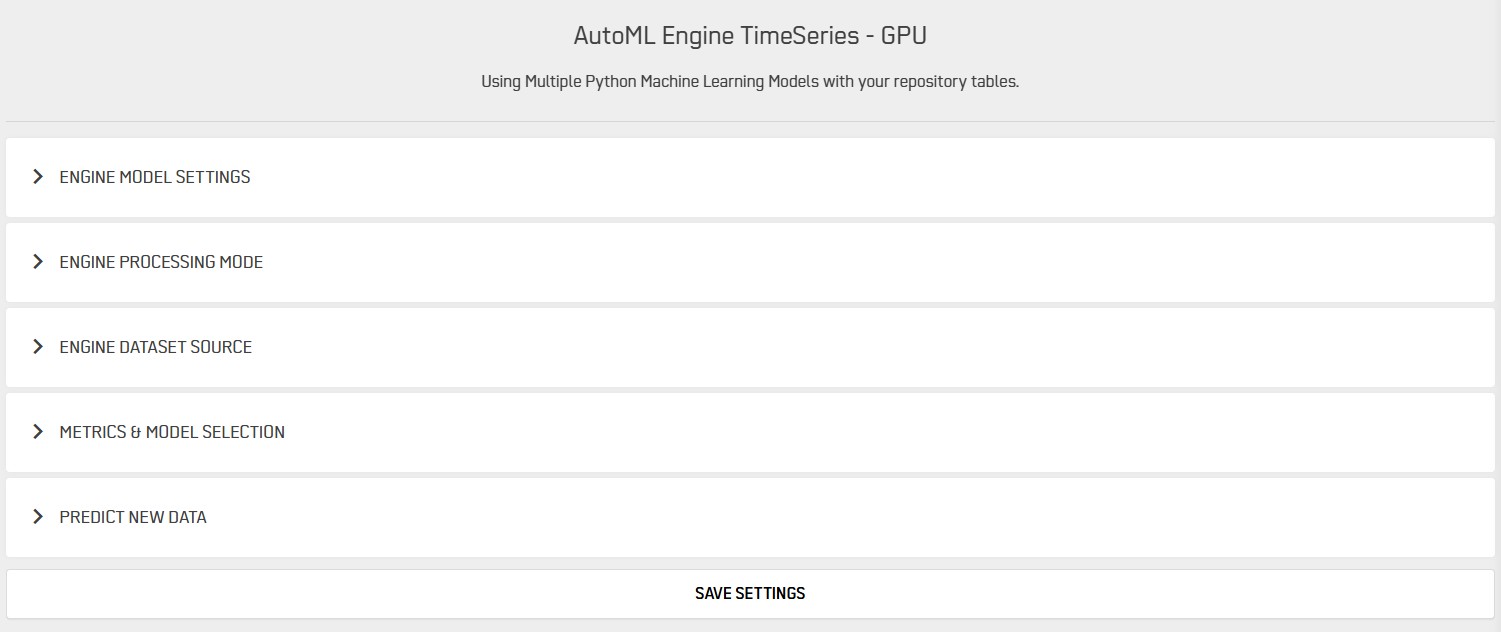
You can now go through the different tabs to setup AutoML Time Series.
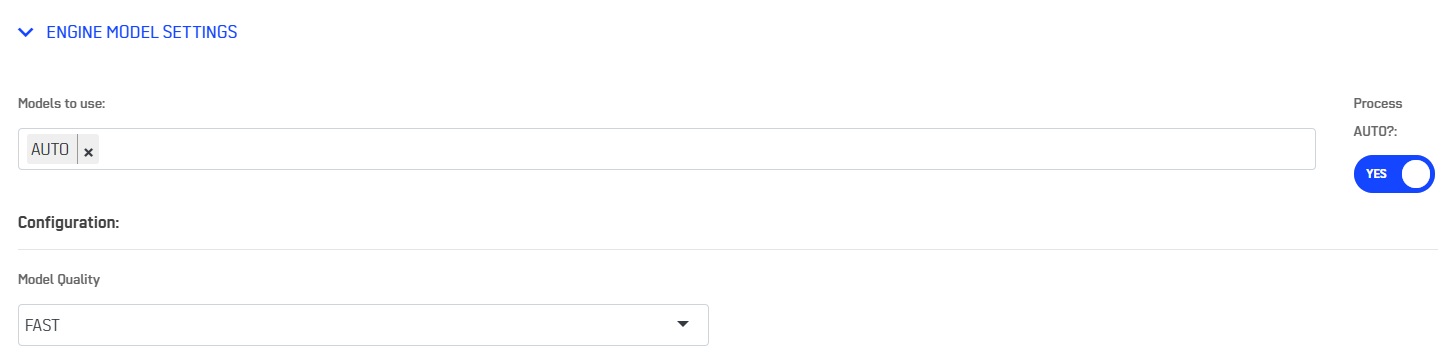
Engine Model Settings
You can select here a list of model to train on your data. You can also let AutoML TimeSeries choose a selection of models automatically using the button AUTO on the right side. The choice of models will then depend on your selection in the Model quality field. This will also impact the training time.
The interface offers flexibility to select the data in your table. You can skip row at the beginning of the table using the Data offset field. You can also select how much rows of data you want to use for training after the offset using the Train length field. If you want to take all available data just tick the box max. It will automatically calculate the data length available depending on the different options.
The Prediction length determines how many new timestamp if predicted after the selected input data.
By default, a Mean value is predicted. You can add a list of quantiles to add in the output table.
At last, you can select the Metrics that will be use to evaluate the models.
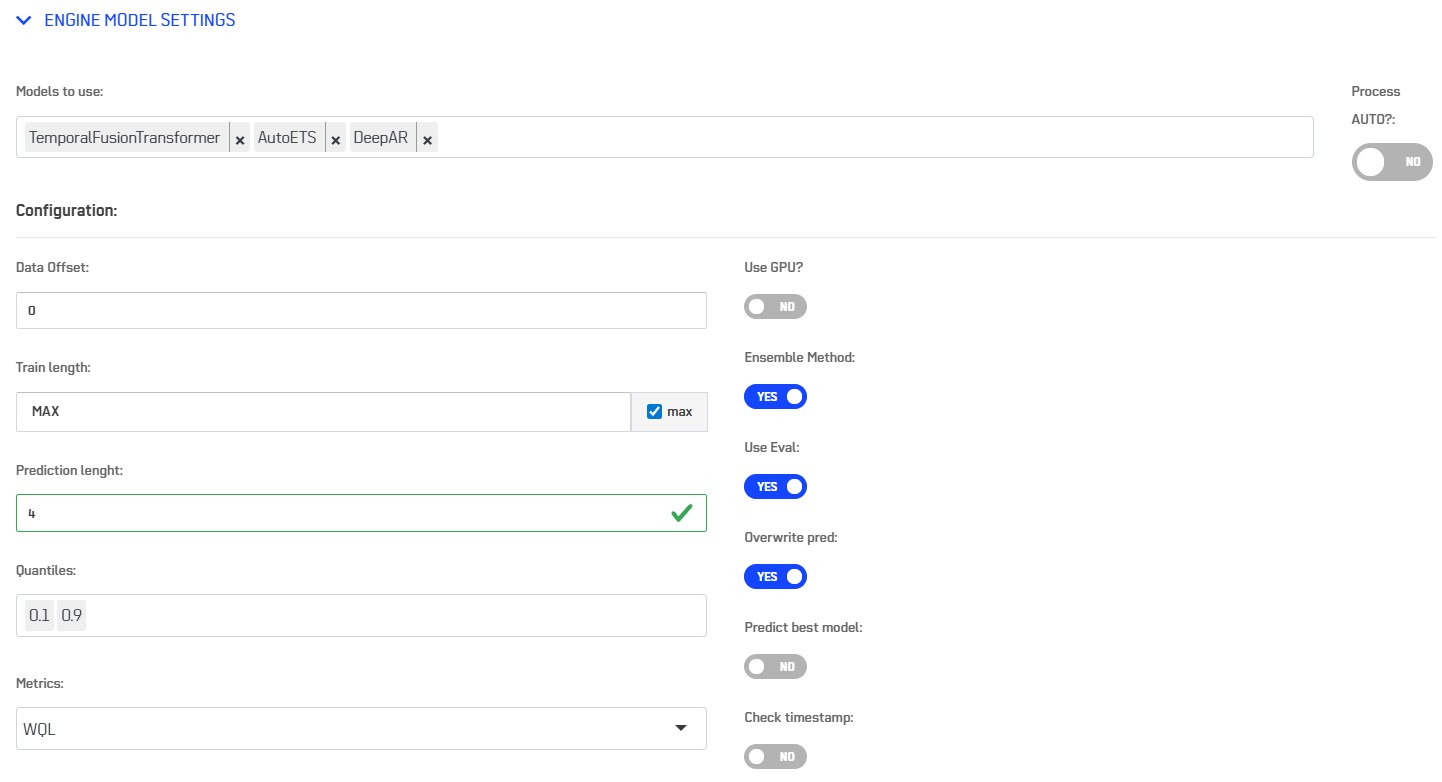
The Ensemble Method option allows to build a better solution by weighting results of the best models. The score will appear in the Metrics and Model Selection tab under the name WeightedEnsemble.
The Use Eval option activate the use of the last rows of data to calculate a better evaluation. The evaluation prediction are stored within a table whose name is formed by the source table name and the suffix _ts_eval in the working repository.
The Overwrite pred option protects the output table if it has already been created.
The Predict best model will automatically perform prediction for the best model and write the prediction output table, immediately at the end of the training phase. The prediction is stored within a table whose name is formed by the source table name and the suffix _ts_pred in the working repository.
The Check timestamp option verify that the Time column contains a regular timestamp.
Engine Processing Mode
You can select between Training and Predict mode.
- Training mode: After setting up ENGINE MODEL SETTINGS and ENGINE DATASET SOURCE, press SAVE SETTINGS at the bottom and RUN button on the left menu. It can take a moment to run. Once the selected models are trained once, it will generate the prediction on the best model if the option has been selected above.

- Predict mode: after training, select your model, specify the output table name and RUN.
Engine Dataset Source
In the section Project Repository, select the table defined in the Repository Table object (see Project requirement). You will be able to see a preview of your table.
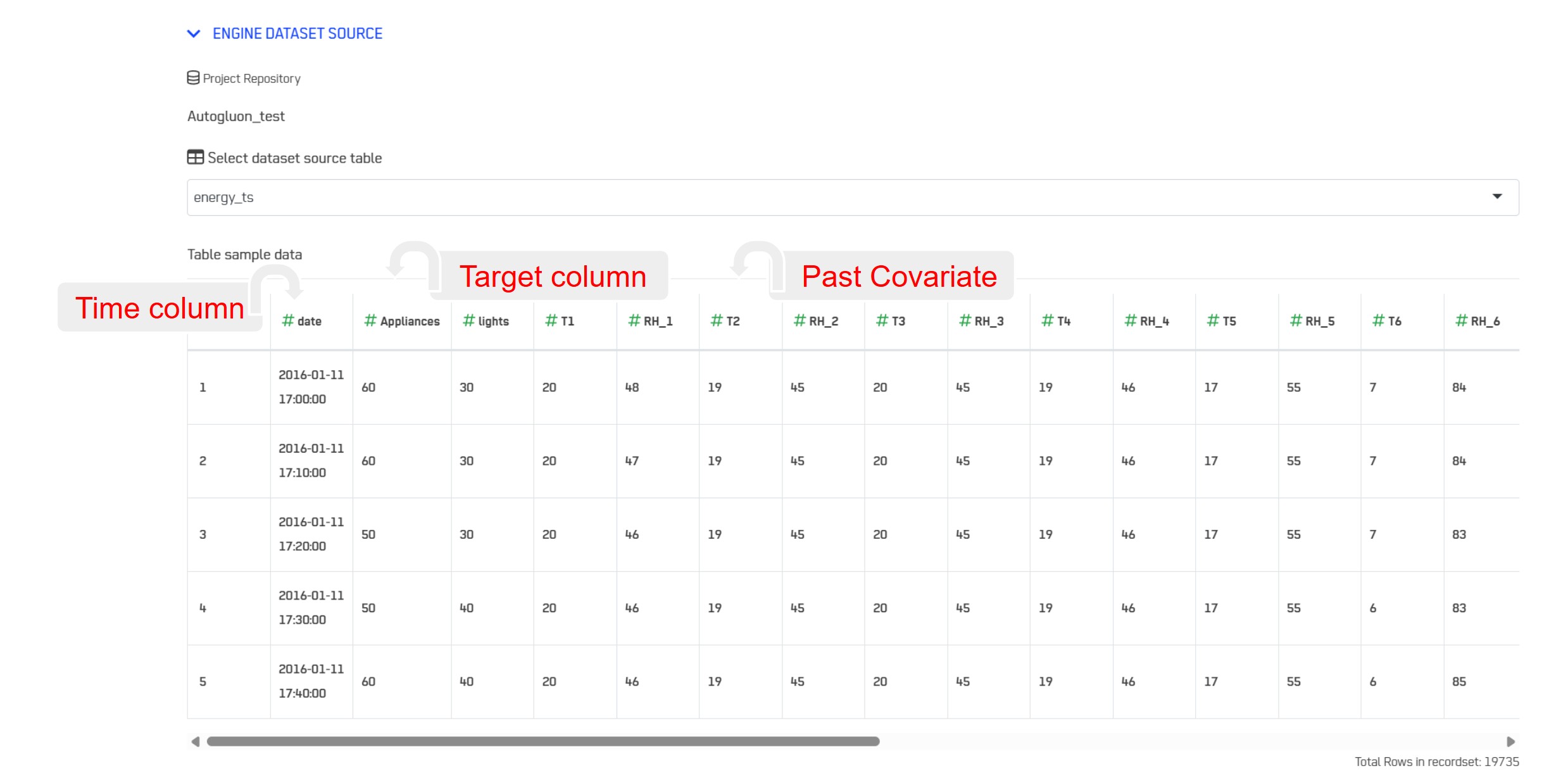
The following table shows consumption of energy for Appliances and Lights in a house, and includes sensors data in different rooms (temperature and humidity). It contains a column with timestamps that will be use as the Time column, a Target column (Appliances) and you can optionaly select one or several past covariate columns, which are data correlated to the target column that can help the algorithm to detect a pattern. The table does not contained Known covariate data. It could be a column that differentiate week days and weekend when the consumption of energy is different. The future of this type of data is known and should be added in the last rows of the source table if Known covariate data is used.
You can now fill the fields Time column, Target Columns and eventually Past covariates and Know Covariates.
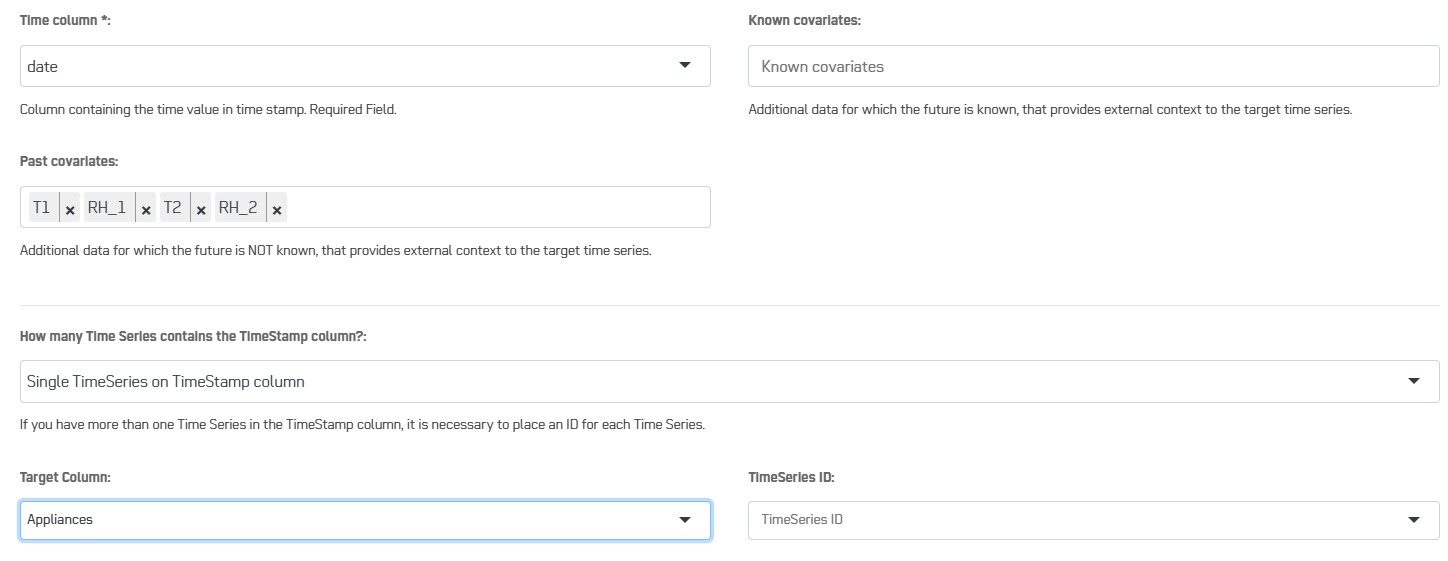
The interface offers flexibility on the data selection and on how to stucture your data. You can make prediction on a single time series or several time series.
- The data to predict is in a single column : select Single TimeSeries column. There are 2 possible situations:
- The column contains a single time series i.e. the Time column contains one occurance of the timestamp range; you don't need to specify the field TimeSeries ID.
- The column contains several time series i.e. the Time column contains several occurances of the timestamp range. In that case, you need to use an extra column TimeSerie ID to distinguish the different time series. All rows of a time series should have the same value in the TimeSeries ID column and the data of the timeseries needs to be consecutive without holes in the timestamp (regular interval).
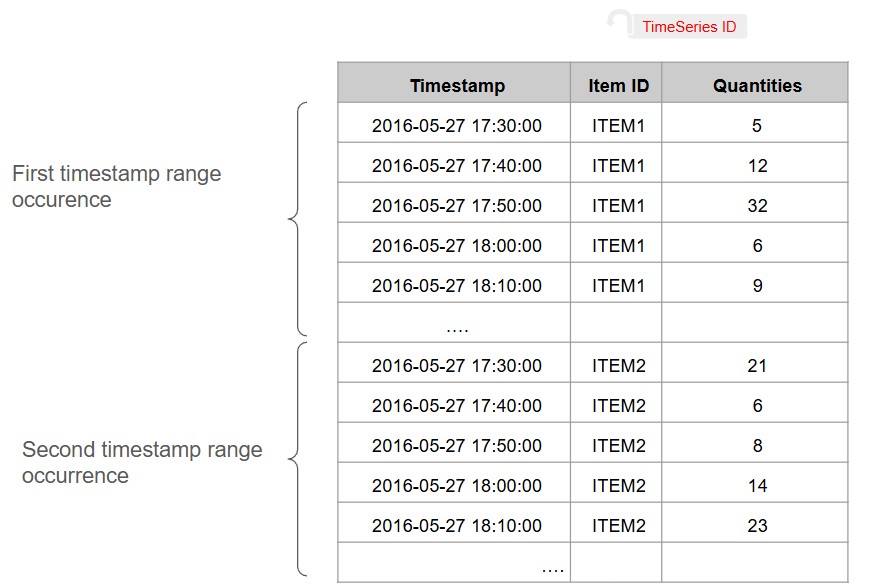
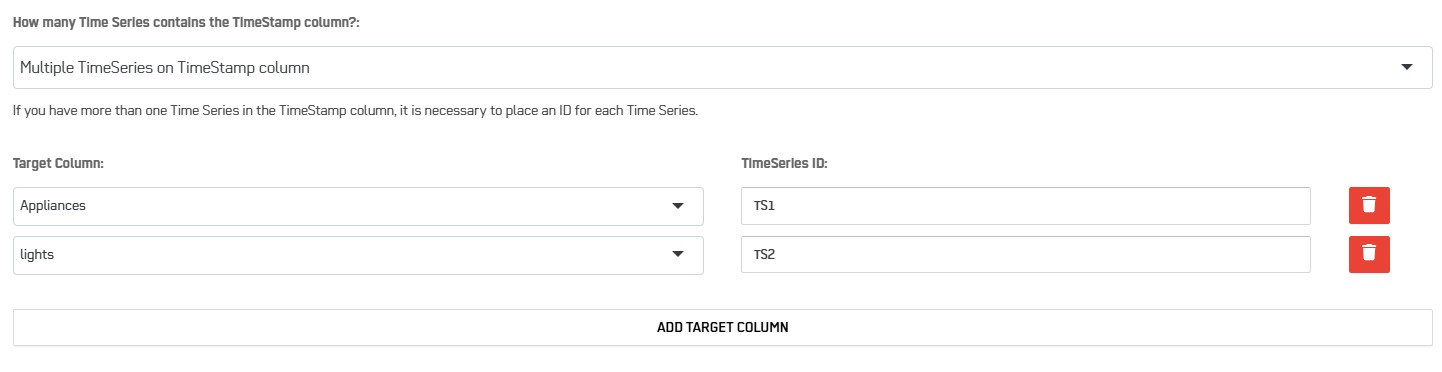
- The data to predict is spread over different columns: select Multiple TimeSeries columns. You can use the button ADD TARGET COLUMN to add data to predict. All the target columns are timed with the Time column that should contain a single timestamp range. For each Target Column, you need to define a TimeSeries ID (this is a single value for each target).
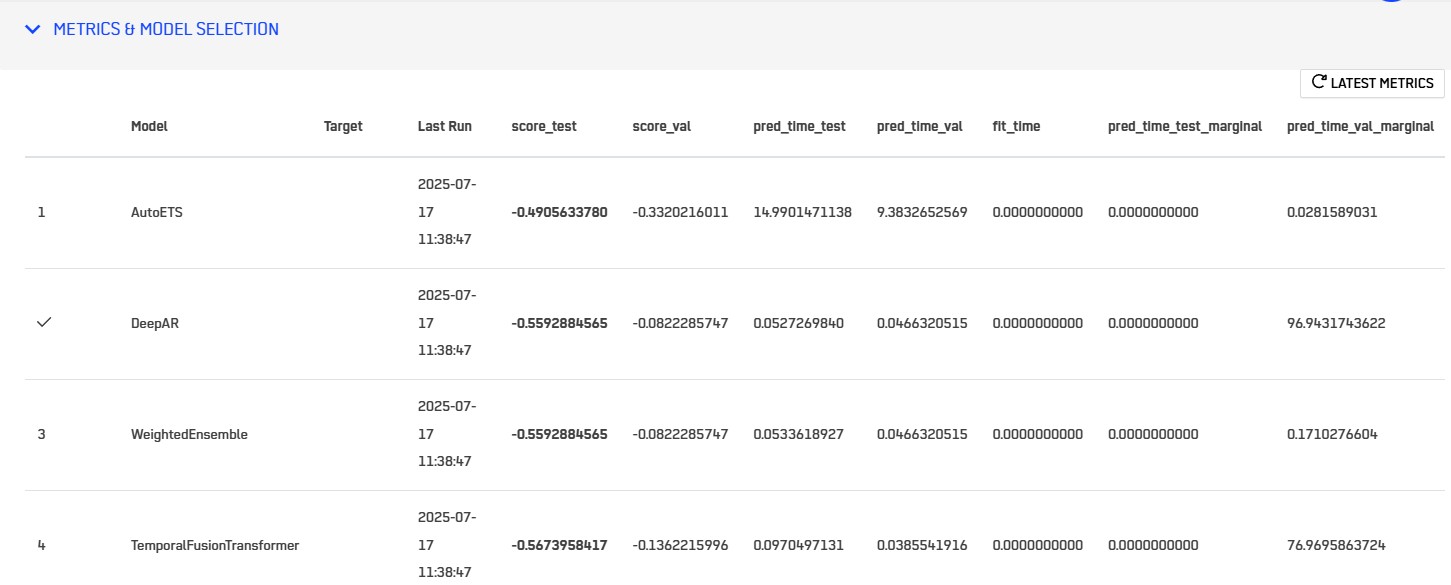
Metrics and Model Selection
After running the training mode, press button LATEST METRICS to refresh result. For scores, smallest number will mean better prediction. You can select here the model for which you want to run a new prediction.
Predict New Data
If you are in Predict Mode, specify the table name where prediction for the selected model will be stored. You can then press the button RUN to perform the prediction.

Updated about 1 year ago