
Data Governance - Data Sensitivity Classification
Data Sensitivity Classification is a critical component of data governance that involves categorizing data based on its level of sensitivity, importance, and the potential risk associated with its exposure or unauthorized access. This process is essential for ensuring that sensitive information is adequately protected while still being accessible to those who need it to perform their duties effectively.
Purpose and Importance:
The primary purpose of data sensitivity classification is to prevent data breaches and ensure compliance with various regulatory requirements such as GDPR, HIPAA, and other privacy laws that govern personal and sensitive data. By classifying data, organizations can apply appropriate security measures and controls that correspond to the sensitivity of the data. This not only protects the organization from legal and financial repercussions but also helps in maintaining trust with customers and stakeholders.
Classification Levels:
Typically, data is classified into several categories, such as public, internal-only, confidential, and highly confidential, although these categories can vary depending on the organization's specific needs and the regulatory environment.
- Public: Data that can be made available to the general public without any risk to the organization. Examples include press releases, marketing materials, and published financial reports.
- Internal-only: Data that is not sensitive but is intended for use only within the company. This might include internal policies, training materials, and certain operational data.
- Confidential: Data that could cause damage to the organization if disclosed, such as business plans, financial records, or any information that provides a competitive edge.
- Highly Confidential: This includes any data that would likely lead to severe damage if exposed, such as personally identifiable information (PII), protected health information (PHI), security details, and legal documents.
Meta Data on Knowledge Nodes
Configuring the classification levels and term of usage of each Knowledge Node is important for good Data Governance.
In the Properties tab of each Knowledge Node, the Meta Data section allows you to configure the Category, Icon, Color, Tags, and Owners for the node. You can also add custom Extra Data fields by clicking + Add Extra Data and entering a label for the new metadata field.
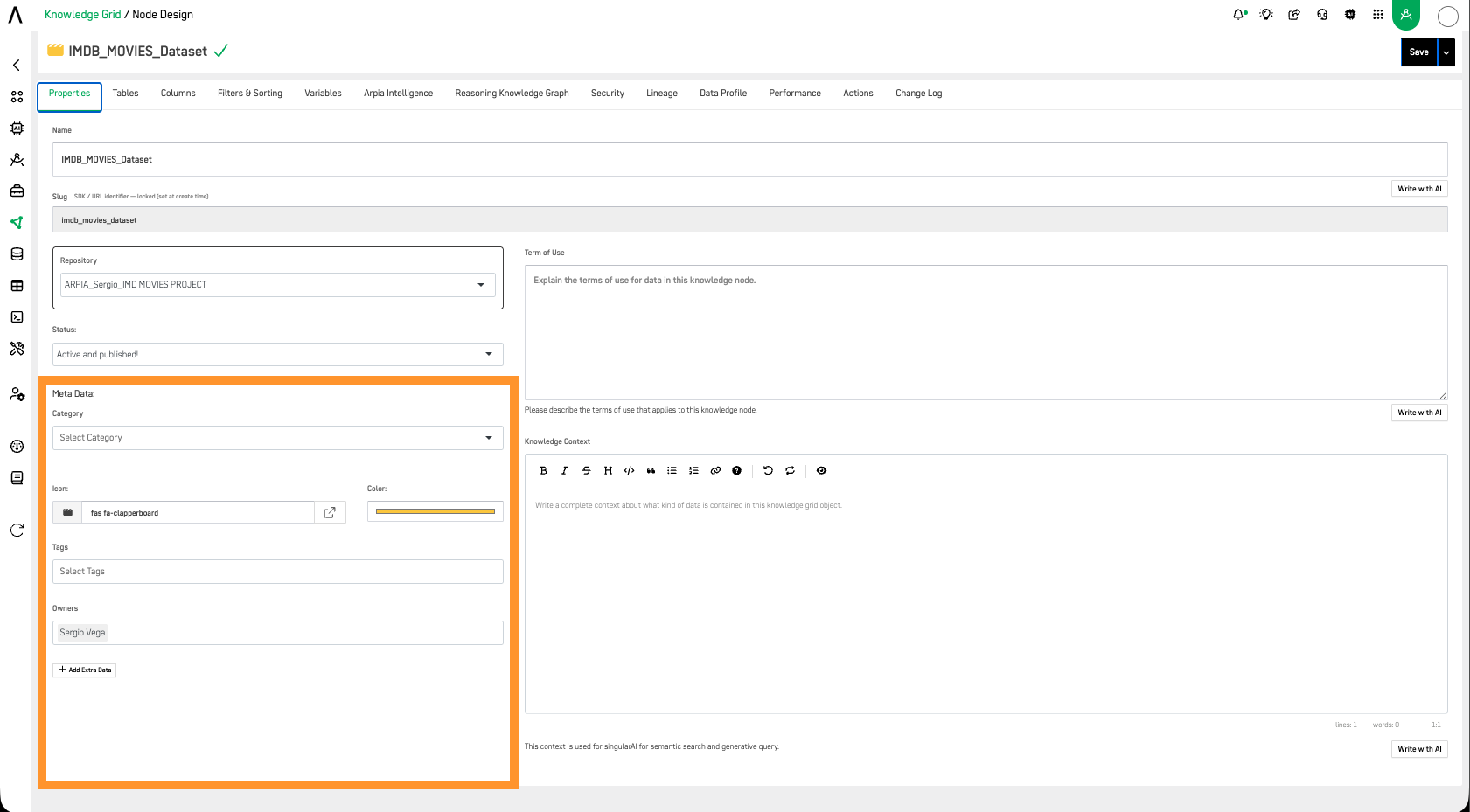
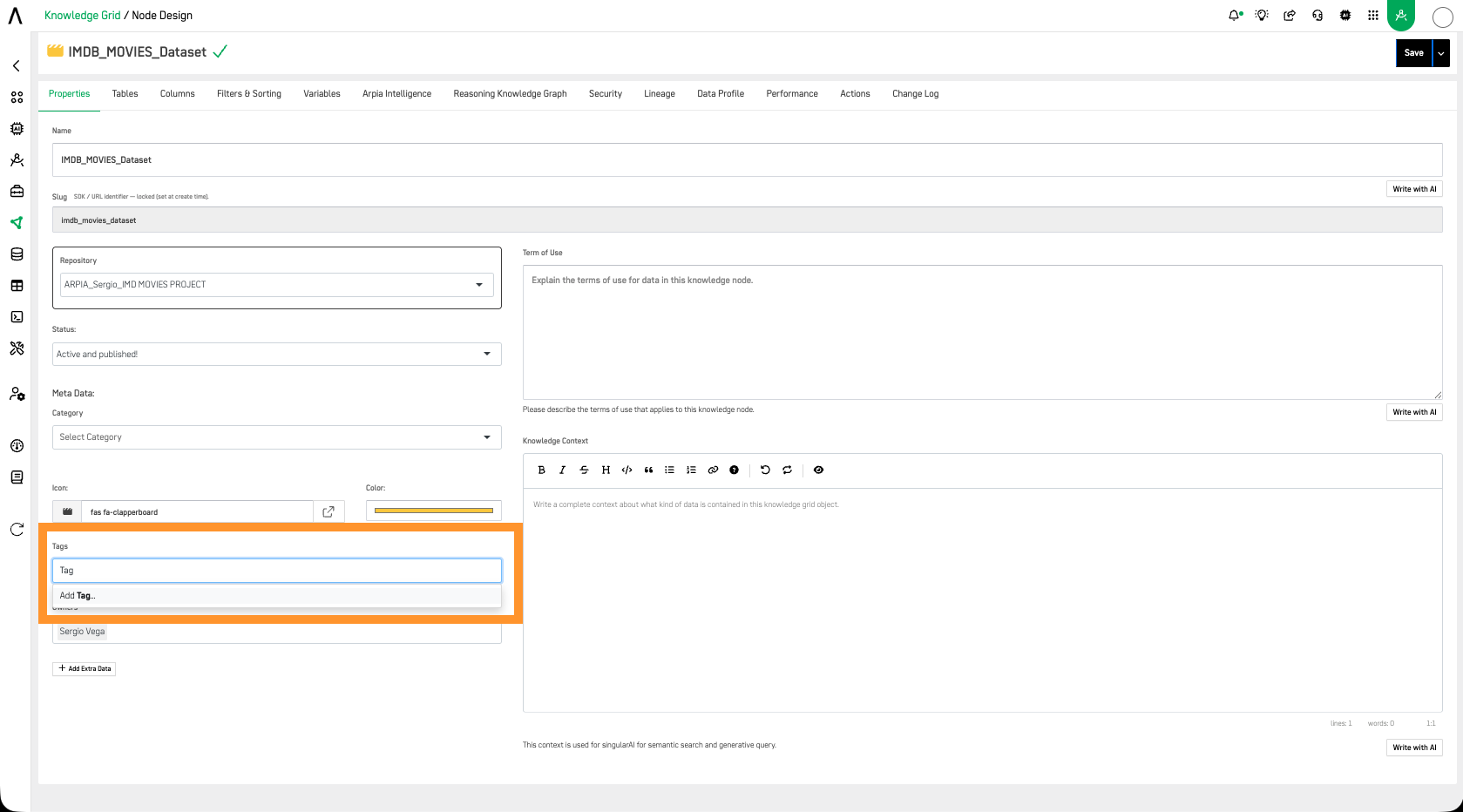
Implementation and Access Controls:
Once classified, the data must be protected according to its classification level. This might involve encrypting highly confidential data, implementing access controls that limit data access based on user roles, or setting up audit trails to monitor data access and usage.
The Security tab on the Knowledge Node provides insights on which profiles and users are accessing the node, and shows any pending user access requests to this node.
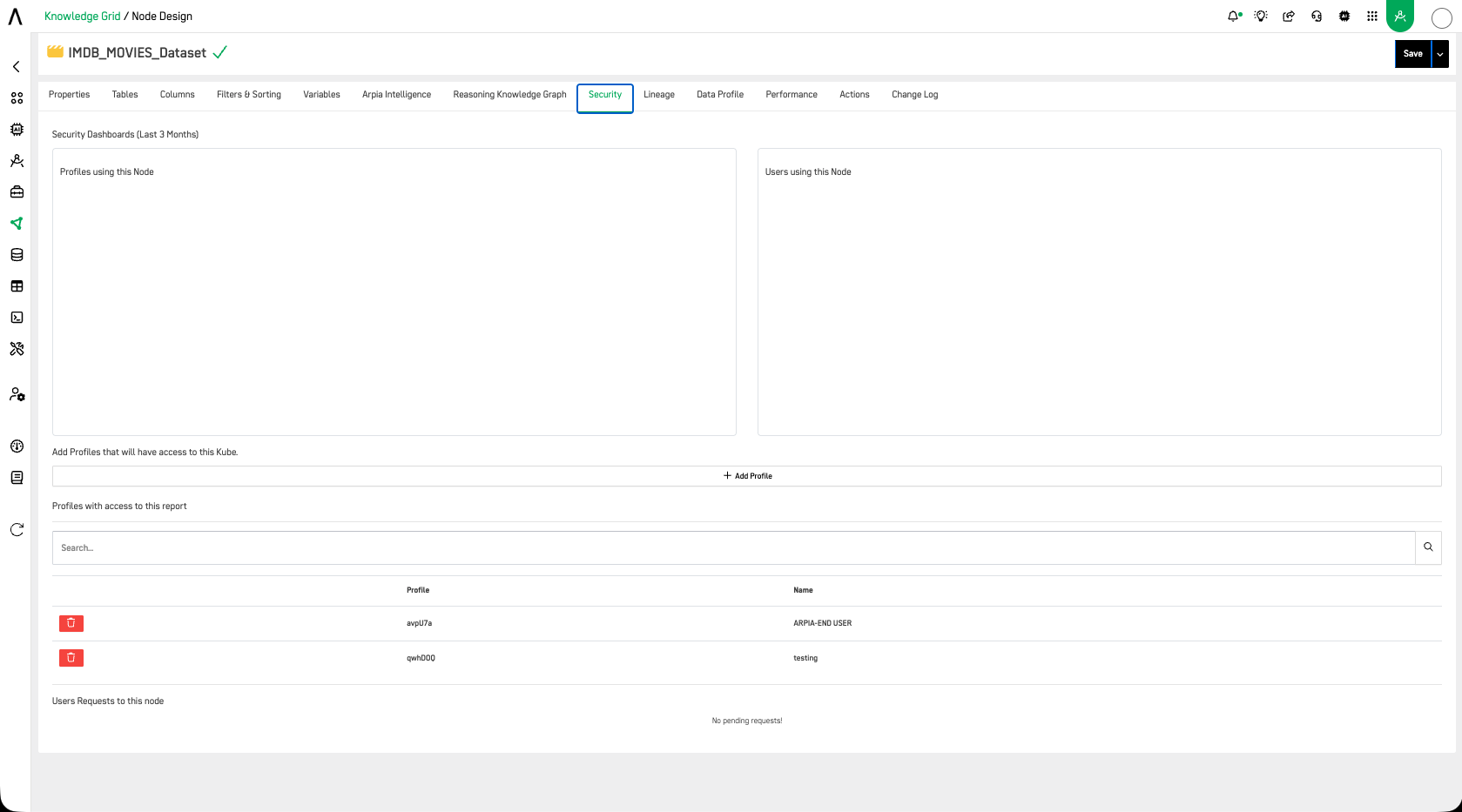
Regular reviews and audits are crucial to ensure that the classification remains accurate over time and that the data protection measures are effective. As data changes, or as the organizational environment or legal requirements evolve, reclassification might be necessary.
A Data Admin can manage all these access controls using the security tools, user profiles, and the Knowledge Node Security tab for managing what users have access to data and how they use it.
🏛️ Compliance Framework Alignment
Data sensitivity classification directly supports the following compliance frameworks:
| Requirement | ISO 42001 | SOC 2 Type 2 | ISO 27001 | GDPR | HIPAA | NIST AI RMF | DORA |
|---|---|---|---|---|---|---|---|
| Data classification & sensitivity tagging | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Access controls based on classification | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| PII / PHI identification & protection | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| Term of use & purpose limitation | ✅ | ✅ | ✅ | ✅ | |||
| Regular reclassification & review | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Node-level security & access governance | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Why Data Sensitivity Classification Supports Each Framework
🤖 ISO 42001 — AI Management System
ISO 42001 requires organizations to identify and manage the risks associated with data used in AI systems, including ensuring that sensitive data is appropriately classified and protected before it feeds AI processes. ARPIA's Knowledge Node classification system — combining Category, Tags, Term of Use, and node-level access controls — allows organizations to define and enforce sensitivity boundaries around AI-consumed data, supporting the standard's requirements for responsible AI data governance.
🔐 SOC 2 Type 2 — Security, Availability, and Confidentiality
SOC 2's Confidentiality trust service criteria require organizations to identify confidential information and implement controls to protect it throughout its lifecycle. ARPIA's classification system enables organizations to tag nodes as confidential or highly confidential, restrict access via Security Profiles, and audit who has accessed sensitive nodes — providing the evidence of confidentiality controls that SOC 2 auditors require.
🛡️ ISO 27001 — Information Security Management
ISO 27001 Annex A requires organizations to classify information according to legal requirements, value, criticality, and sensitivity, and to apply appropriate handling procedures based on that classification. ARPIA's metadata fields — including Category, Tags, and custom Extra Data — directly support the creation and maintenance of an information classification scheme, while the node-level Security tab enforces the corresponding access controls.
🇪🇺 GDPR — General Data Protection Regulation
GDPR requires organizations to identify personal data, apply data minimization and purpose limitation principles, and restrict access to those with a legitimate need. ARPIA's sensitivity classification capabilities allow organizations to tag nodes containing PII with appropriate labels, configure Terms of Use to document the lawful basis for processing, and enforce access controls that ensure only authorized users can reach sensitive data — directly supporting Articles 5, 25, and 32.
🏥 HIPAA — Health Insurance Portability and Accountability Act
HIPAA requires covered entities to identify PHI across their systems and implement appropriate safeguards based on the sensitivity of that information. ARPIA's node-level classification — combined with column-level Data Governance tags for Description and Column Purpose — allows organizations to identify and document PHI fields explicitly, while Security Profiles and the node Security tab enforce the access controls required by the HIPAA Privacy and Security Rules.
🧭 NIST AI RMF — AI Risk Management Framework
The NIST AI RMF's GOVERN and MAP functions require organizations to identify sensitive data used in AI systems and assess the associated risks. ARPIA's classification system supports these functions by enabling organizations to tag Knowledge Nodes with sensitivity levels, document their purpose and ownership, and restrict AI agent access to only those nodes for which a legitimate use has been defined — reducing the risk of AI systems accessing or exposing data beyond their intended scope.
⚡ DORA — Digital Operational Resilience Act
DORA requires financial entities to classify their ICT assets and data according to criticality and sensitivity, and to implement controls proportionate to that classification. ARPIA's node classification system — combined with profile-based access controls and the node Security tab — provides the asset classification and access governance capabilities required to demonstrate that sensitive financial data is identified, protected, and accessible only to authorized users and systems.
Updated 26 days ago