
Data Governance - Data Relationship
Data relationships in the context of data management and database design are fundamental to structuring and interpreting the vast arrays of data that organizations handle. These relationships help define how data in one table is associated with data in another, impacting everything from data integrity to the efficiency of data retrieval and the effectiveness of data analyses.
In AP you may configure relationships between Knowledge Nodes using the Data Points option under the Knowledge Catalog menu.
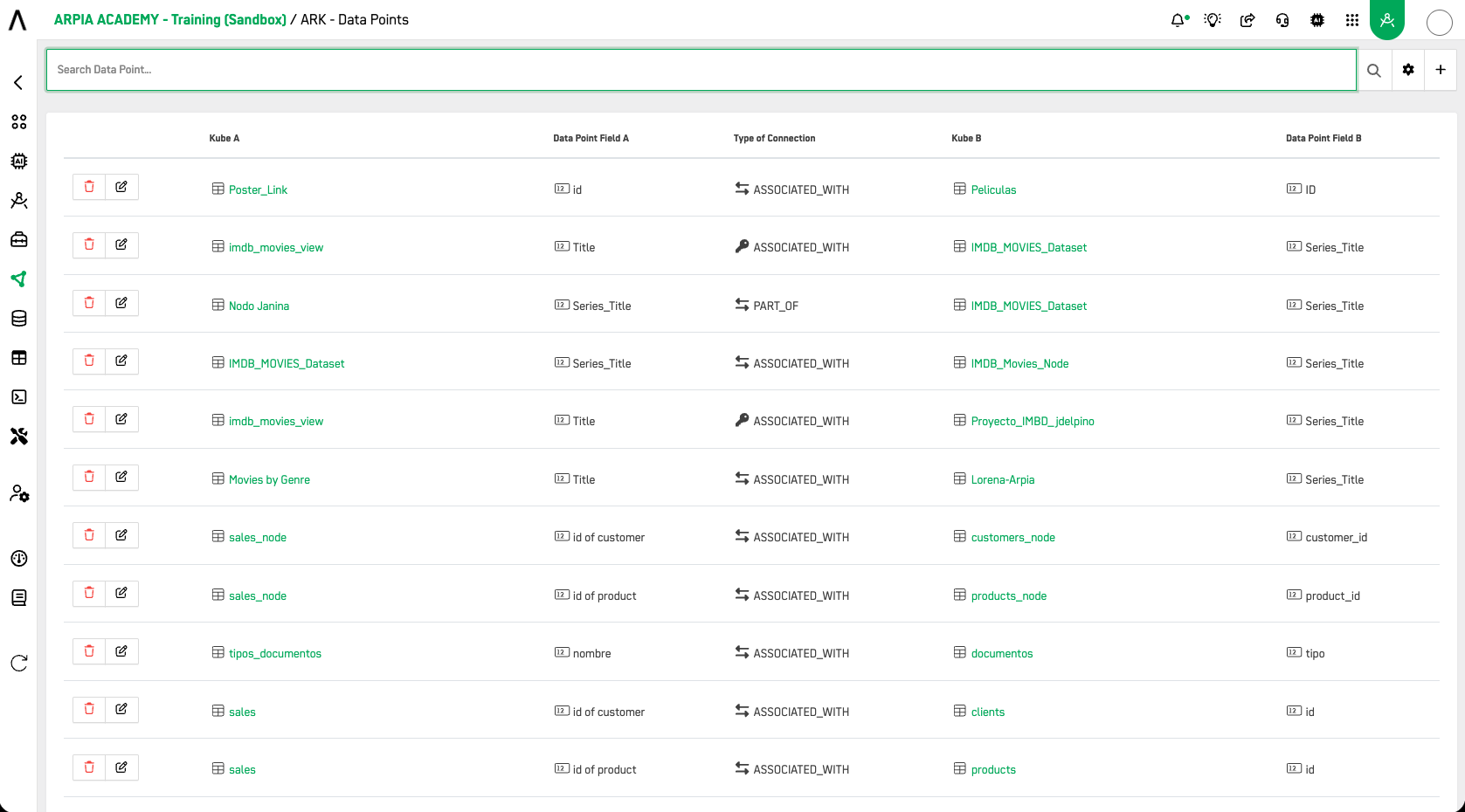
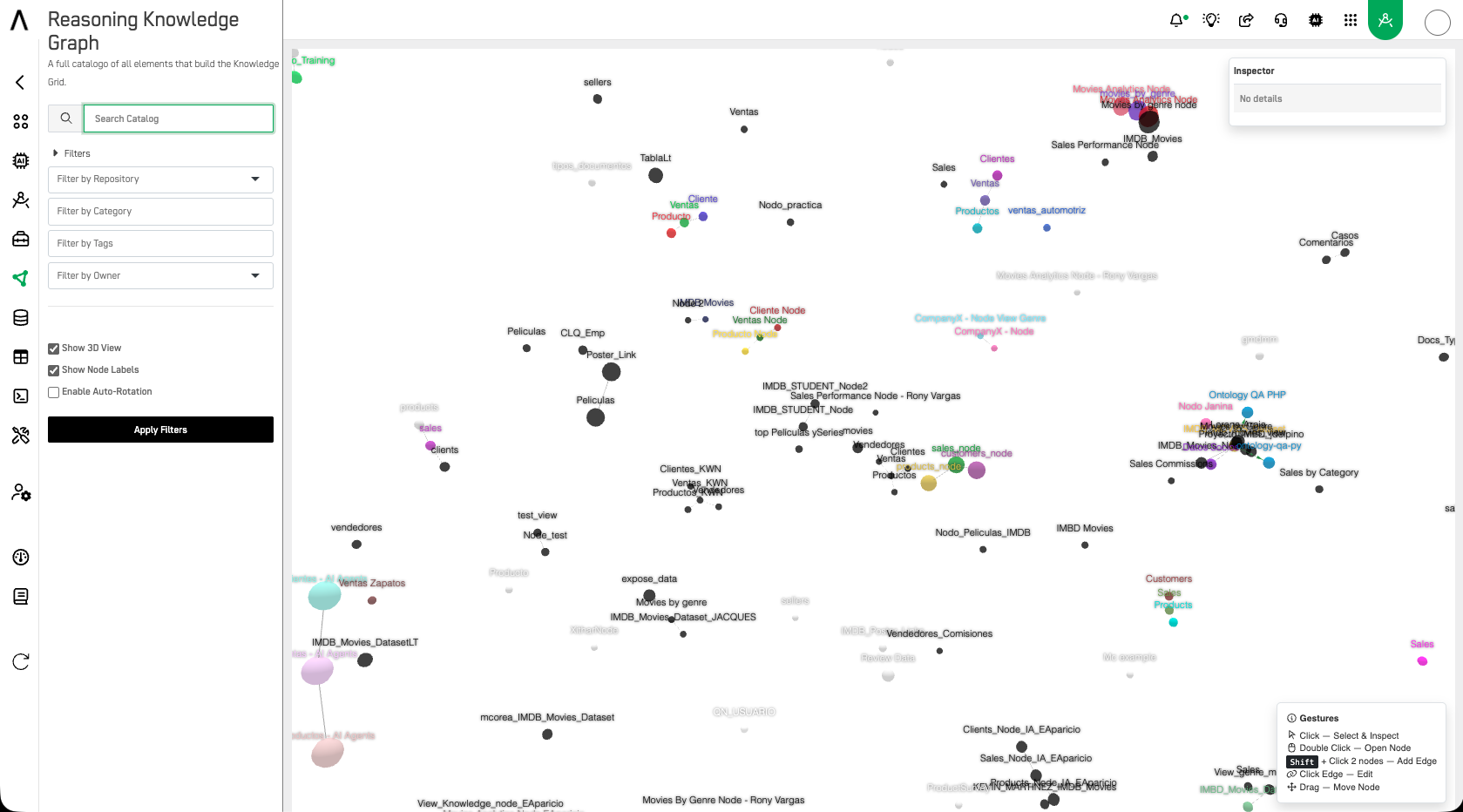
These relationships can be seen in the Reasoning Knowledge Graph as shown in the following image:
Types of Data Relationships
The most common types of data relationships found in relational databases are:
-
One-to-One: This relationship exists when one record in a table is linked to only one record in another table. For example, a database containing employee information might link each employee to a specific parking space record in a parking management table. Each employee has one and only one designated parking space, and each parking space is assigned to only one employee.
-
One-to-Many: This is the most common relationship, where a record in one table can relate to multiple records in another table. Consider a business with a database containing a table for employees and another for department assignments. A single department might have many employees, but each employee is assigned to just one department.
-
Many-to-Many: In this relationship, multiple records in one table can relate to multiple records in another table. For example, in a university database, a student might register for multiple courses, and each course might have multiple students enrolled. This relationship typically requires a junction table to manage the associations between the two entities effectively.
In AP you can configure two types of relationships: a primary and a normal relationship. Primary relationships are used for better understanding of node relationships and other subsystem configurations for understanding the way the Knowledge Catalog is configured.
Importance of Data Relationships
Understanding and managing data relationships are crucial for several reasons:
-
Data Integrity: Relationships help maintain data accuracy and consistency through referential integrity constraints. For example, foreign keys ensure that a record relating to another cannot exist without the corresponding record in the linked table.
-
Query Efficiency: Properly defined relationships allow more efficient data queries. Database management systems can optimize query performance by understanding how tables relate and where to look for linked data.
-
Data Analysis: Relationships are vital for complex data analyses and reports. They enable the joining of tables to provide comprehensive insights that consider multiple dimensions of the data, such as combining customer, order, and product data to analyze purchasing patterns.
-
Database Normalization: Relationships play a key role in database normalization, a process designed to reduce redundancy and improve data integrity by organizing tables according to relationships and dependencies.
Challenges in Managing Data Relationships
Despite their importance, managing data relationships comes with challenges:
-
Complexity in Design: Designing a database that effectively models all necessary relationships without excessive complexity or redundancy requires careful planning and expertise.
-
Performance Issues: As the number of relationships and the size of the data grow, maintaining performance becomes challenging. Overly complex joins or large transaction volumes can slow down query response times.
-
Maintenance Overhead: Relationships can create dependencies that complicate updates, deletions, and insertions. For example, deleting a record that acts as a foreign key in another table might require cascading deletions or updates, adding overhead and potential for errors.
In summary, data relationships are a cornerstone of database design and data management, essential for maintaining data integrity, enabling efficient queries, and supporting complex analyses. However, they require thoughtful implementation and ongoing management to balance benefits against potential complexity and performance costs.
🏛️ Compliance Framework Alignment
Managing data relationships directly supports the following compliance frameworks:
| Requirement | ISO 42001 | SOC 2 Type 2 | ISO 27001 | GDPR | HIPAA | NIST AI RMF | DORA |
|---|---|---|---|---|---|---|---|
| Data integrity & referential constraints | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Data model documentation | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Impact analysis & dependency mapping | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| AI data context & knowledge graph | ✅ | ✅ | |||||
| Query efficiency & performance | ✅ | ✅ | ✅ | ||||
| Cross-node data governance | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Why Data Relationships Support Each Framework
🤖 ISO 42001 — AI Management System
ISO 42001 requires organizations to understand and document the relationships between data assets used by AI systems, ensuring that AI agents operate within a well-defined and governed data context. ARPIA's Data Points and Reasoning Knowledge Graph provide a visual, governed map of how Knowledge Nodes relate to one another — giving AI agents and administrators a clear picture of data dependencies, enabling context-aware reasoning and reducing the risk of AI systems drawing incorrect inferences from unrelated data.
🔐 SOC 2 Type 2 — Security, Availability, and Confidentiality
SOC 2 requires that data processing systems operate with integrity — meaning data relationships and constraints must be maintained consistently over time. ARPIA's primary and normal relationship types enforce referential integrity across Knowledge Nodes, ensuring that data consumed by applications and AI systems remains logically consistent and that changes to one node do not silently corrupt downstream processes.
🛡️ ISO 27001 — Information Security Management
ISO 27001 requires organizations to understand and document information flows and dependencies as part of asset management and risk assessment. ARPIA's Reasoning Knowledge Graph provides a live, queryable map of all inter-node relationships — enabling organizations to identify which assets are dependent on which data sources, assess the impact of changes, and maintain an accurate information asset register that reflects actual data architecture.
🇪🇺 GDPR — General Data Protection Regulation
GDPR's data minimization and purpose limitation principles require organizations to understand how personal data flows between systems and whether cross-system relationships could result in unintended exposure or processing. ARPIA's Data Points allow organizations to explicitly define and govern the relationships between nodes containing personal data, making it easier to identify and remediate relationships that could violate GDPR's principles of data minimization or storage limitation.
🏥 HIPAA — Health Insurance Portability and Accountability Act
HIPAA requires covered entities to understand how PHI flows through and between their systems. ARPIA's relationship mapping — particularly the primary relationship type used for cross-node governance — enables organizations to document and audit how PHI-containing nodes relate to other data assets, supporting both the Privacy Rule's minimum necessary standard and the Security Rule's requirement to protect PHI across all system components.
🧭 NIST AI RMF — AI Risk Management Framework
The NIST AI RMF's MAP function requires organizations to identify data relationships and dependencies that could affect AI system behavior or introduce bias. ARPIA's Reasoning Knowledge Graph provides the dependency mapping required to identify how changes in one node could propagate to AI outputs, enabling organizations to assess and mitigate risks associated with interconnected data assets in AI pipelines.
⚡ DORA — Digital Operational Resilience Act
DORA requires financial entities to map ICT asset dependencies and understand how disruptions in one system component could cascade to others. ARPIA's Data Points and Reasoning Knowledge Graph provide a live dependency map of all Knowledge Node relationships — enabling organizations to perform the ICT dependency mapping, impact analysis, and resilience testing required under DORA's operational resilience framework.
Updated 26 days ago