
Arpia Platform Model Catalog: AutoML (AutoGluon & YOLO) and the Multi-Provider LLM Gateway
Overview of AutoML and Large Language Models Compatible with the Arpia Platform
🧠 AutoML Capabilities: AutoGluon and YOLO Models
Arpia’s AutoML functionality leverages AutoGluon and can be extended through YOLO for specialized, high-speed image processing and object detection. The two serve different needs: AutoGluon excels at classification, YOLO at real-time detection. Through Arpia Managed Services, clients can access configurations tuned for complex scenarios, such as high-speed detection in camera, drone, and radar footage.
🔍 AutoGluon Models
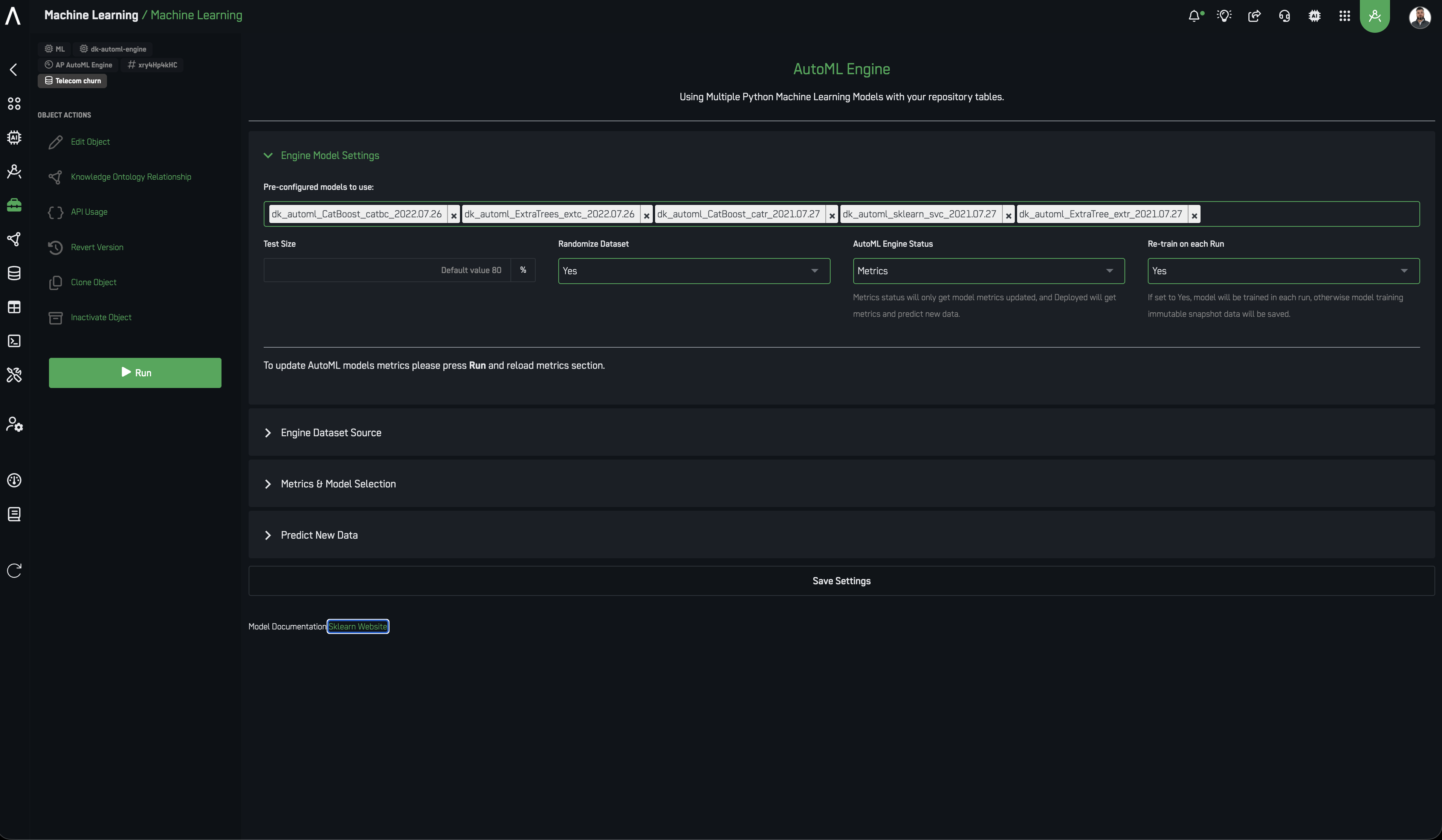
AutoGluon is built for general-purpose machine learning, excelling in structured (tabular) data, image classification, and time series forecasting. Its key strengths:
- Model selection and ensembling — automatically chooses optimal models and builds ensembles to boost predictive accuracy and robustness.
- Image classification — ideal where high-level categorization is needed, such as quality control or content tagging.
- Time series analysis — supports trend forecasting and predictive maintenance on sequential data.
- Advanced configurations for complex use cases:
- Model compatibility and conversion — for real-time detection, AutoGluon models export to ONNX, enabling high-speed inference engines (e.g., NVIDIA TensorRT).
- Inference optimization — converted models can be optimized with TensorRT or OpenVINO for high-speed deployment, reaching latency comparable to YOLO.
🚀 YOLO Models
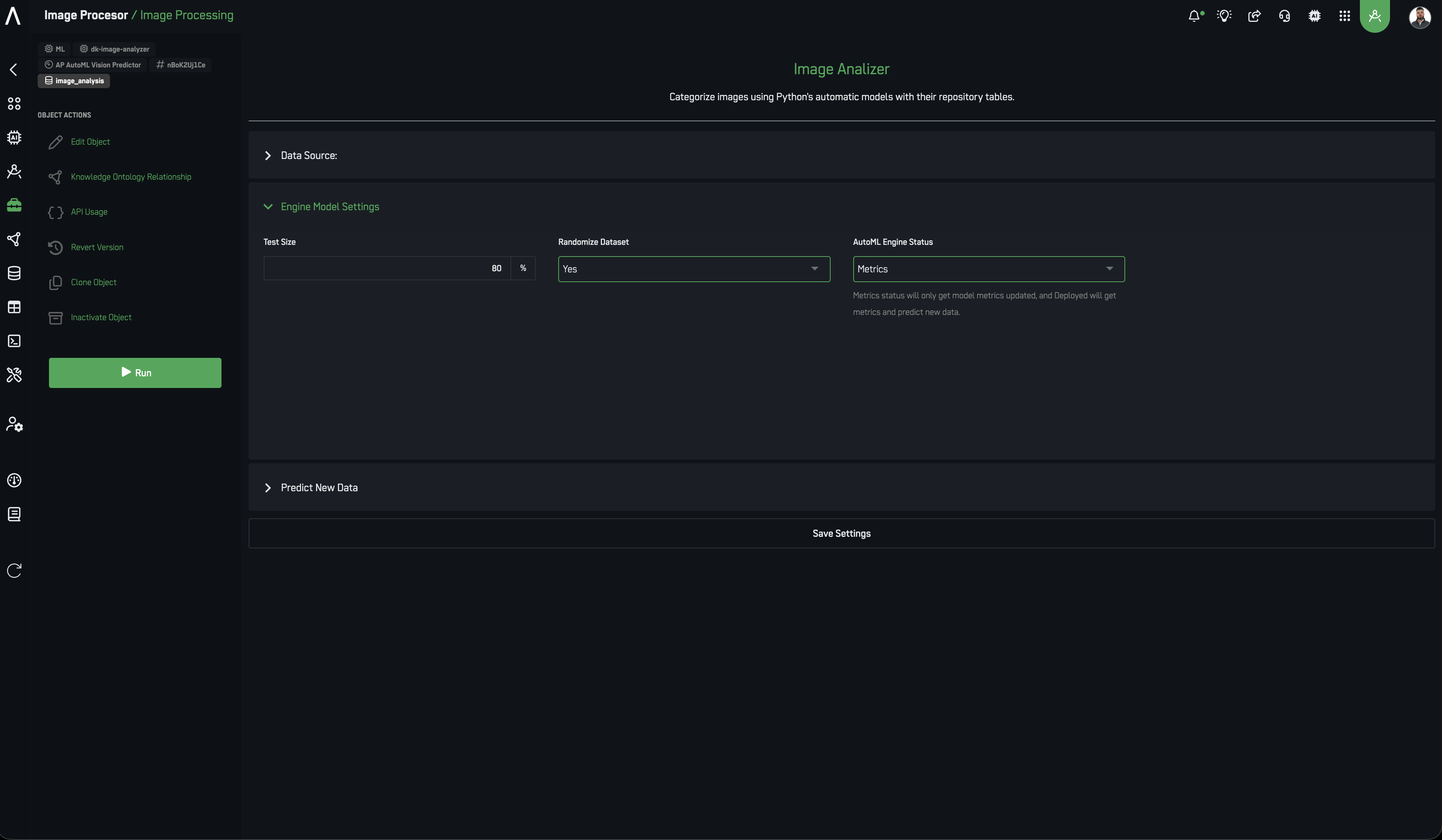
YOLO (You Only Look Once) models are optimized for real-time object detection — identifying and locating objects within images or video streams. They are an excellent fit for applications that demand rapid, continuous processing, such as live surveillance or real-time analytics.
- Hybrid YOLO–AutoGluon pipeline — for cases needing both detection and high-accuracy classification, YOLO acts as a front-line detector, quickly identifying and cropping regions of interest. Those regions pass to an AutoGluon classifier for refined categorization, balancing YOLO’s speed with AutoGluon’s accuracy.
💬 Large Language Models (LLMs) for Generative AI
Arpia’s platform includes a multi-provider LLM gateway for generative and analytical tasks, supporting both cloud-hosted frontier models and locally or self-hosted open-weight models. This lets organizations meet privacy, performance, and cost requirements by choosing the right model for each step in a workflow.
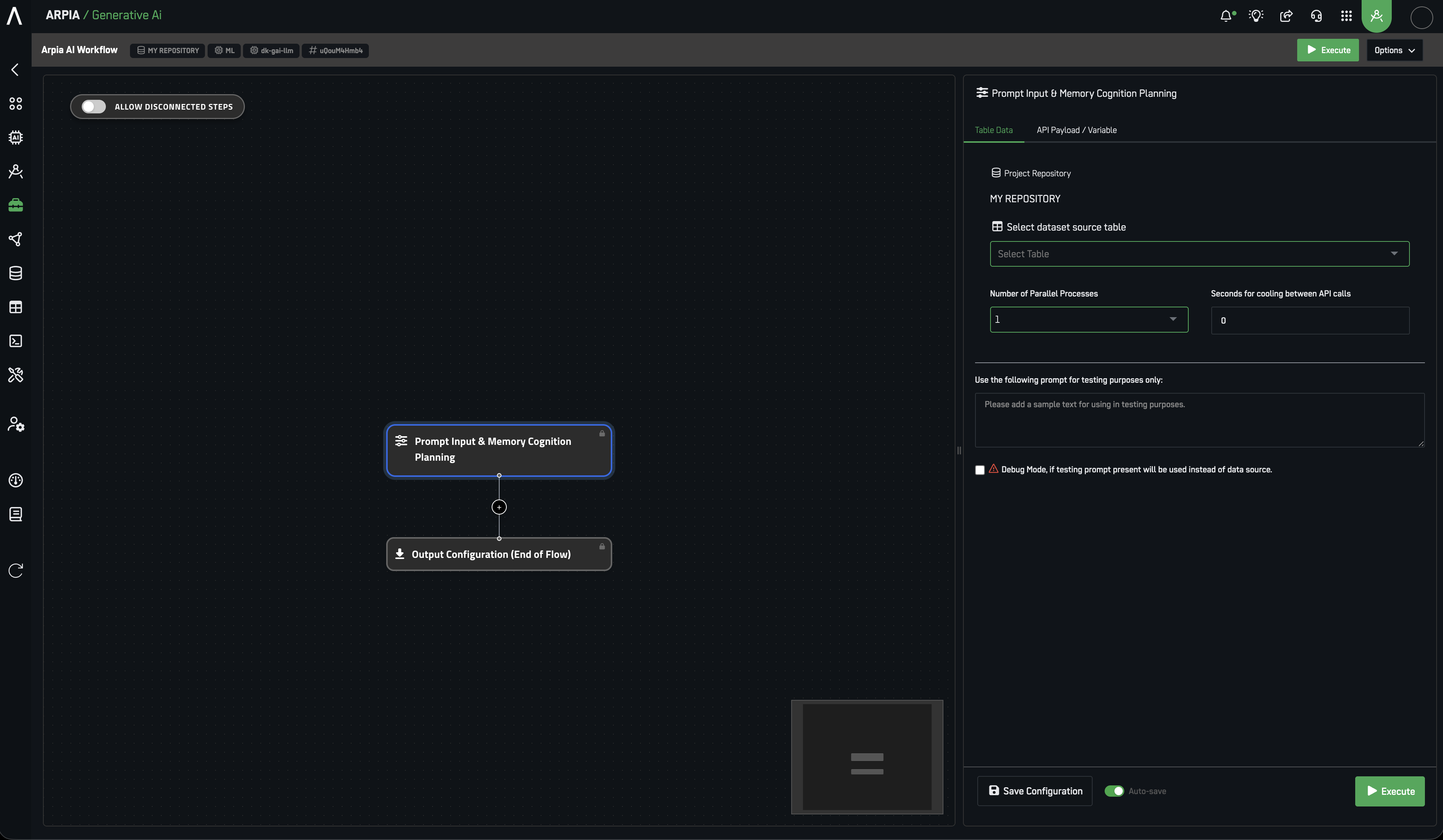
Single source of truth — the AI Model Table. The active models in your WorkArea, plus their routing, context windows, and billing, are managed in the AI Model Table (AI Orchestrator → AI Governance → Configuration). This document describes the model ecosystem; the AI Model Table reflects the current enabled catalog. Model versions evolve quickly — always confirm the active models, context limits, and pricing in the AI Model Table rather than relying on the version names listed here.
🌐 Available Models — Two Tiers
Arpia routes requests across multiple providers through a unified gateway, so a single workflow can mix providers and tiers. The catalog has two commercial tiers:
- 🟢 Base Models (Included) — covered by your Enterprise contracted tokens, with no additional per-use charge.
- 🔴 Frontier Models (Pay-Per-Use) — premium models billed separately per consumption; not included in any plan.
Model identifiers use the
provider/modelconvention from the AI Model Table, and all models support a 1M-token context. Per-model credit costs and billing mode are intentionally not listed here — they change over time and live in the AI Model Table (AI Orchestrator → AI Governance → Configuration) and the Pricing documentation.
🟢 Base Models — Included
| Provider | Available models |
|---|---|
| OpenAI | openai/gpt-4o, openai/gpt-4o-mini, openai/gpt-5-nano |
| Anthropic | anthropic/claude-haiku-4-5 |
| Mistral | mistralai/mistral-nemo, mistralai/codestral-2501, mistralai/pixtral-large-2411 |
| Cerebras | cerebras/gpt-oss-120b, cerebras/zai-glm-4.7 |
| Groq | groq/llama-3.1-8b-instant, groq/llama-3.3-70b-versatile, groq/gpt-oss-120b |
| xAI (Grok) | grok/grok-4-1-fast-reasoning, grok/grok-4-1-fast-non-reasoning |
🔴 Frontier Models — Pay-Per-Use
| Provider | Available models |
|---|---|
| OpenAI | openai/gpt-5, openai/gpt-5-mini, openai/gpt-5.2, openai/gpt-5.4, openai/gpt-5.4-mini, openai/gpt-5.4-nano, openai/gpt-5.5 |
| Anthropic | anthropic/claude-sonnet-4-5, anthropic/claude-sonnet-4-6, anthropic/claude-opus-4-5, anthropic/claude-opus-4-6, anthropic/claude-opus-4-7, anthropic/claude-opus-4-8 |
google/gemini-2.5-pro-preview |
Provider strengths at a glance
- OpenAI (GPT) — content generation, structured data, agentic and multimodal tasks.
- Anthropic (Claude) — interpretability, safe-AI practices, long context and prompt caching; tiered as Opus (max capability) / Sonnet (balanced) / Haiku (fast, included).
- Google (Gemini) — large context and native multimodal reasoning.
- xAI (Grok) — fast reasoning and non-reasoning variants with real-time data strengths.
- Mistral, Cerebras, Groq — open-weight models served at low latency and cost for high-concurrency or budget-sensitive steps.
For privacy-sensitive, regulated, or air-gapped deployments, self-hosted open-weight models and embedding models (e.g. Jina for semantic search) can be provisioned through Arpia Managed Services.
🔍 Capabilities in Workflow Configurations
- Semantic search — embedding-based search with models like Jina to retrieve relevant data points, enhancing the Knowledge Grid layer.
- Content generation and summarization — cloud LLMs produce structured content, summaries, and responses for data-driven workflows.
- Prompt engineering with structured responses — ensures consistent data formats for downstream applications through contextually aware output.
- Contextual recommendations — uses insights from prior workflow steps to produce relevant recommendations, ideal for decision support or customer interaction.
⚙️ Flexible Workflow Model Selection
Arpia lets you build workflows that combine multiple models, chosen per step for the right blend of:
- Speed & cost — fast Base-tier models (e.g.
claude-haiku-4-5,gpt-5-nano, or Groq/Cerebras-served open-weight models) for real-time, high-volume steps included in your plan. - Reasoning & precision — Frontier pay-per-use models (e.g.
gpt-5.5,claude-opus-4-8) for complex analysis and nuanced language understanding. - Privacy — sensitive steps routed to self-hosted open-weight models (via Managed Services) while cloud models handle the rest of the same flow.
Model selection, routing, and per-model billing are governed centrally by the AI Model Table, so workflows reference capabilities and tiers rather than being hard-wired to a single version.
📋 Use Case Example
A single workflow might run YOLO for rapid object detection on live footage, then AutoGluon for detailed classification of the detected regions. In parallel, Jina performs semantic search on historical data, while a current frontier LLM (a top-tier Claude, GPT, or Gemini model selected in the AI Model Table) generates a summary report combining real-time analysis with historical insight.
The result: high precision, real-time performance, and adaptability — suited for data-intensive operations in a secure environment.
🔔 Conclusion
With both AutoML (AutoGluon / YOLO) and a multi-provider LLM gateway, Arpia offers a robust, flexible platform for advanced data processing, predictive analytics, and real-time intelligence. Because the model landscape moves quickly, the platform decouples workflows from specific versions: workflows target capabilities and tiers, while the AI Model Table maintains the live, governed catalog of models, routing, and billing. The result is a model ecosystem that integrates cleanly into workflows and delivers data-driven insight for the modern enterprise.
Updated about 2 months ago