
Data Governance - Data Lineage and Provenance
Data lineage and provenance refer to the detailed history and lifecycle of data within an organization's data ecosystem. This includes tracking the origin of data, the various transformations it undergoes, and its final form in reports or analyses. Understanding data lineage and provenance is crucial for multiple aspects of data management, including data quality, governance, regulatory compliance, and operational efficiency.
Importance of Data Lineage and Provenance
1. Compliance and Auditing: Many industries are subject to regulations that require firms to maintain transparent records of their data processes. For example, financial institutions must comply with Basel III and Sarbanes-Oxley regulations, which require detailed auditing capabilities and transparency into the data used in financial reporting. Data lineage helps organizations prove compliance by providing a clear trail of data from source to destination, including all intermediate steps.
2. Debugging and Troubleshooting: When errors occur in processed data or reports, understanding the data's lineage allows analysts and IT professionals to trace back through the data transformation pipeline to identify and correct the source of errors. This capability significantly reduces the time and effort required to resolve data quality issues.
3. Impact Analysis: Before implementing changes in the data architecture or business processes, organizations can use data lineage to assess potential impacts. For example, if a source database schema is to be altered, data lineage can help identify all downstream processes, reports, and analytics that will be affected.
4. Data Quality Management: By tracking where data comes from and how it is transformed, organizations can more effectively diagnose and improve data quality issues. This includes identifying sources of inaccuracies, inconsistencies, or outdated information.
Components of Data Lineage and Provenance
1. Source Data: The origin of data, whether from internal databases, external data providers, or other sources. This includes details about the initial data capture mechanisms and formats.
2. Data Transformations: All processes through which the data passes, including data cleaning, merging, aggregation, and any business logic applied. This also covers tools and technologies used for data processing, such as ETL tools, data pipelines, and workflows.
3. Intermediate and Final Data Stores: All storage points where data resides temporarily or permanently, including data warehouses, lakes, and marts. Lineage information includes how data moves between these stores.
4. Consumption: The end use of the data, such as in business intelligence reports, machine learning models, or operational applications. Provenance here includes who accesses the data and for what purpose.
5. Metadata Management: Alongside physical data flows, lineage and provenance also involve managing metadata, which describes the data's attributes, relationships, and dependencies at each stage of its lifecycle.
🔍 Data Lineage at the Knowledge Node Level
The Data Lineage for a Knowledge Node can be seen in the Lineage tab within the Node settings. Here you will see a graphical representation of how the Node is fed, transformed, stored, and shared throughout the AP ecosystem.
The lineage graph displays the full data flow in two views:
Full Graph View — Shows all connected objects across the ecosystem (Nodes count + Links count displayed at the top). Each object is represented as a card showing its type (Node, Table, Reasoning) and name.
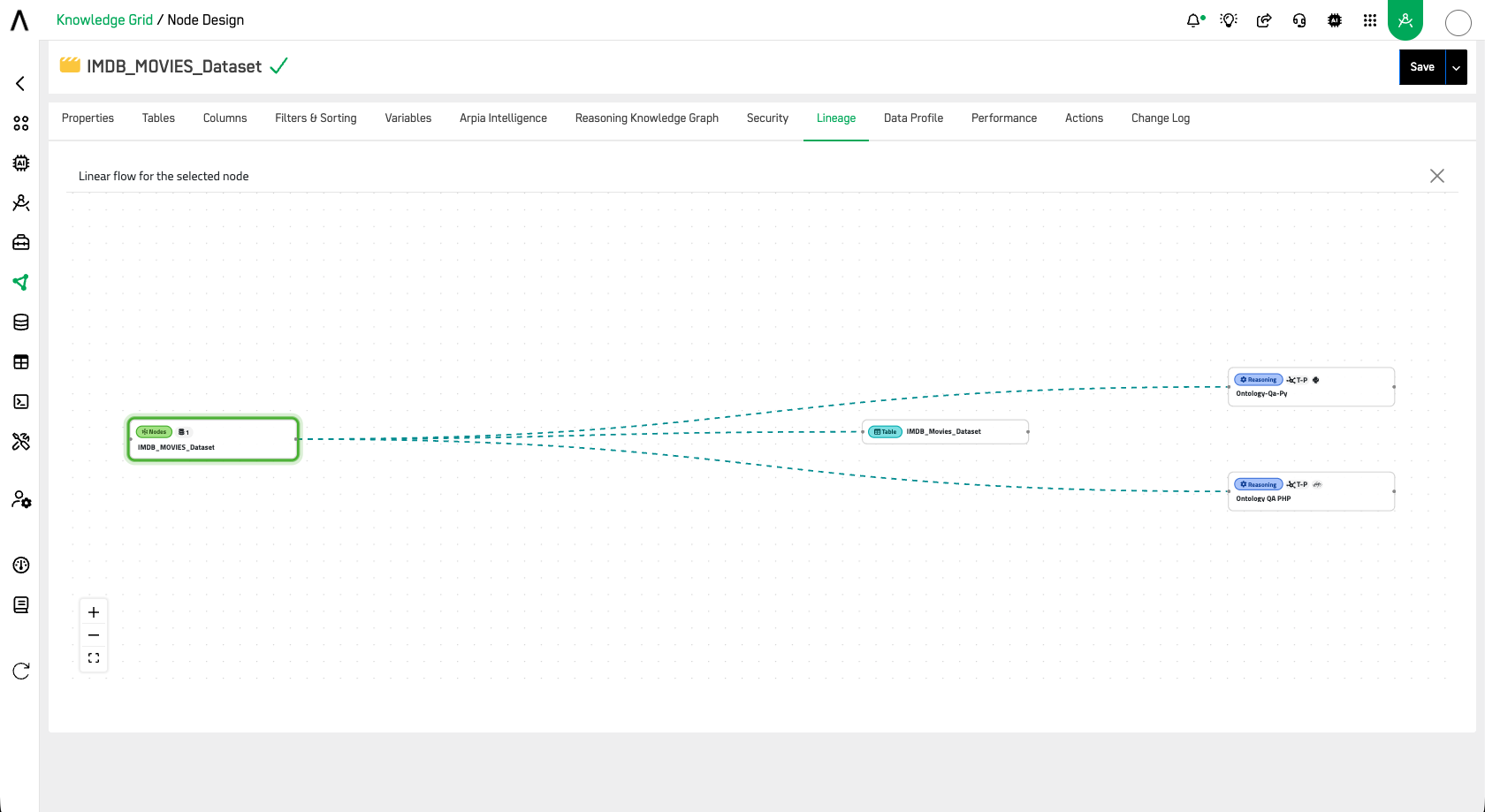
Linear Flow View — Focuses on the selected node and shows its direct upstream and downstream connections in a left-to-right flow: Knowledge Node → Table → Reasoning Flow objects.
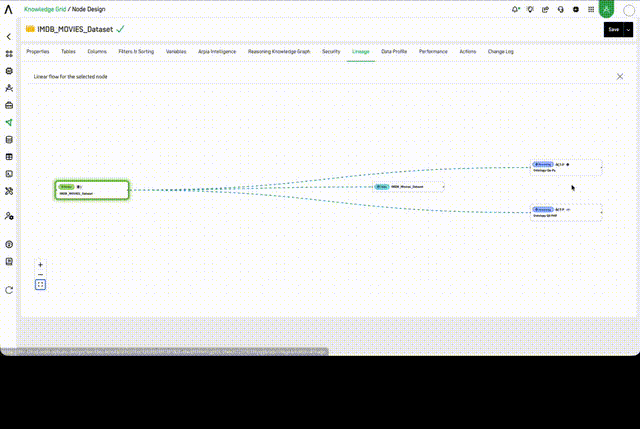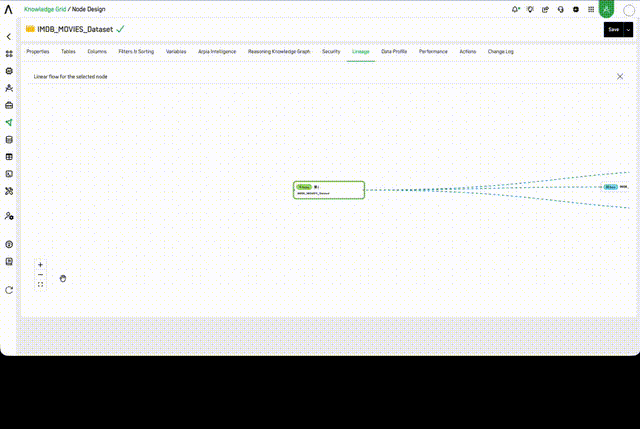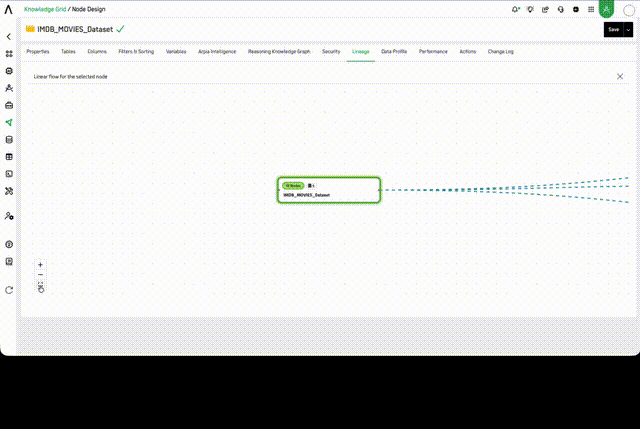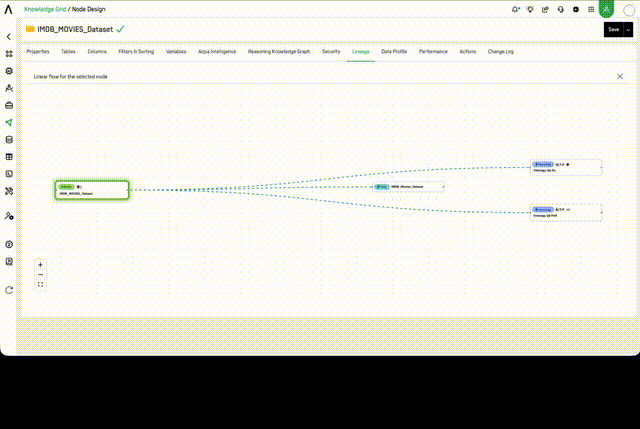
Each object in the graph is interactive. Hovering over a node reveals a context menu with quick actions:
- Knowledge Nodes — shows an OPEN action to navigate directly to the Node Design
- Tables — shows an OPEN action to view the underlying data table
- Reasoning Flow objects — shows OPEN OBJECT (opens the Workshop object) and OPEN PROJECT (opens the Reasoning Flow project)
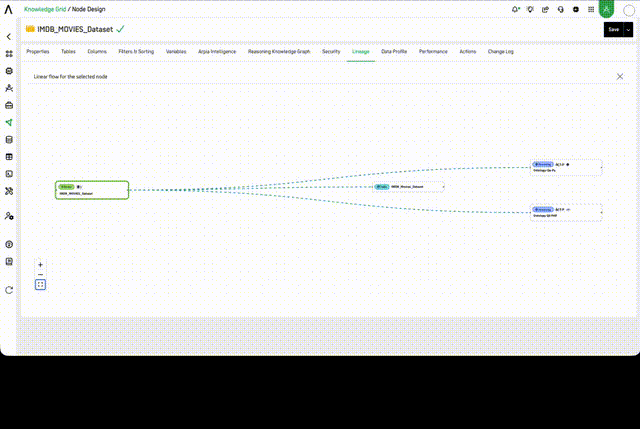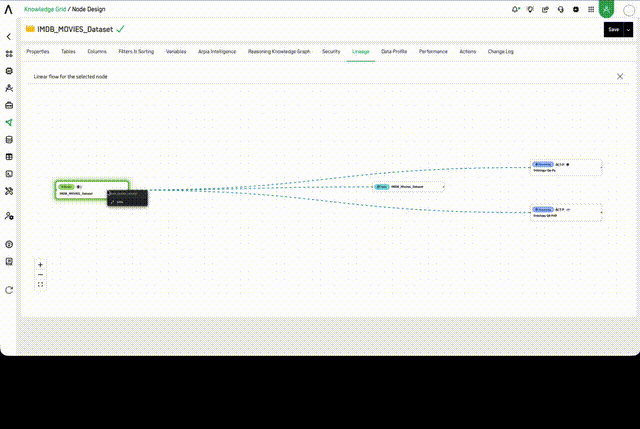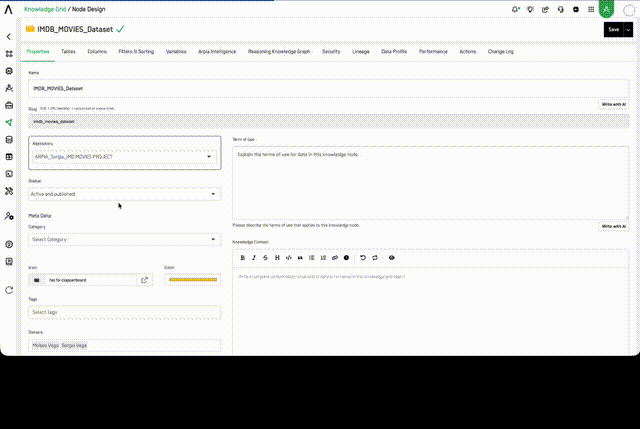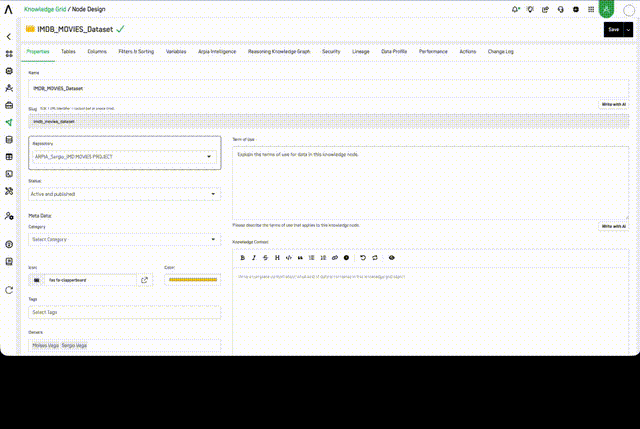

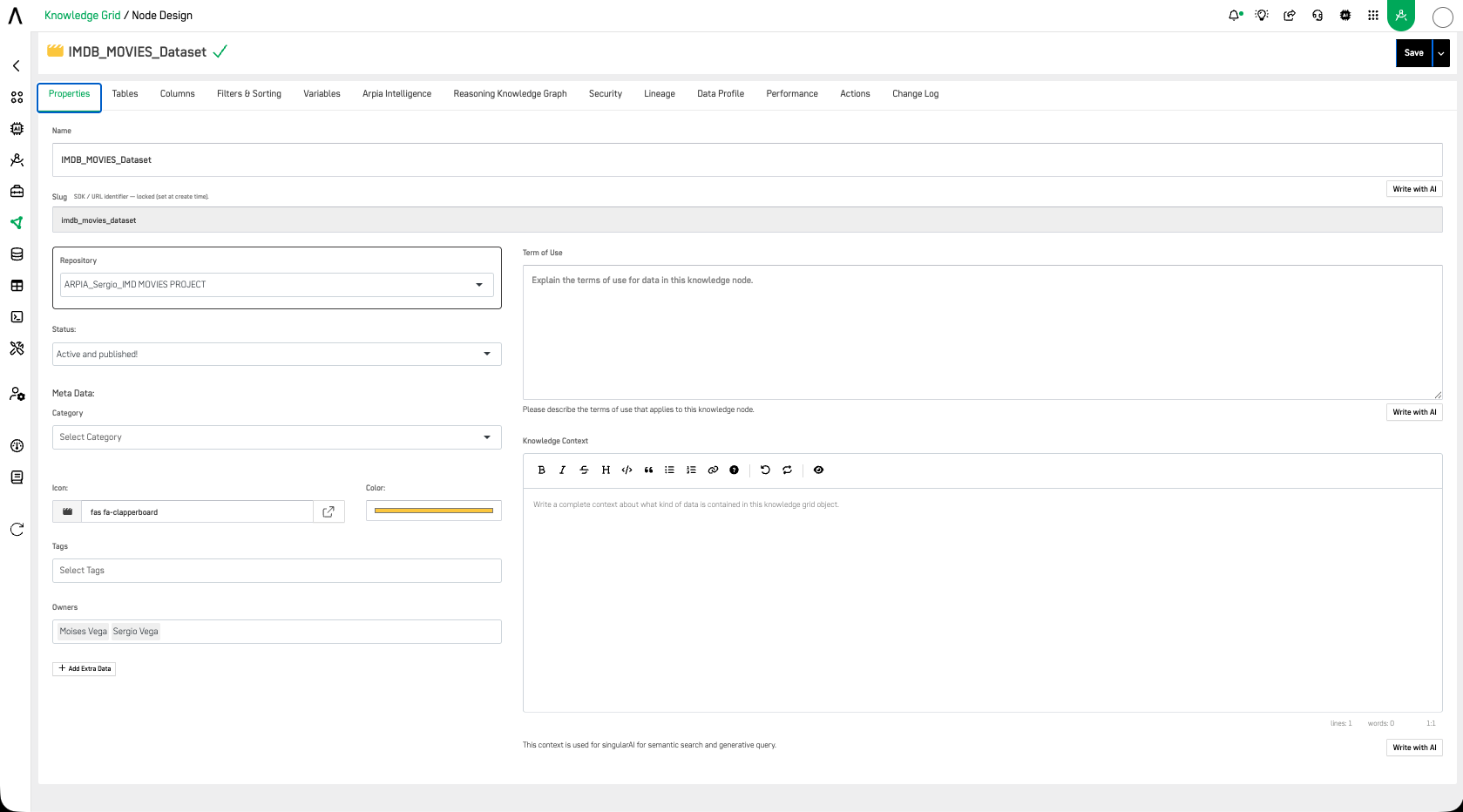
🧩 Knowledge Node Properties
Each Knowledge Node includes a Properties tab where you can configure its core identity and governance metadata:
- Name — The display name of the node
- Slug — The SDK / URL identifier, locked at create time
- Repository — The data repository the node is connected to
- Status — Active and published, draft, or inactive
- Meta Data — Category, Icon, Color, and Tags for classification and visual identification
- Owners — The users responsible for this node
- Term of Use — A plain-language description of the terms that apply to data in this node (AI-assisted writing available)
- Knowledge Context — A rich-text field describing what kind of data is contained in this node, used by AI agents for context-aware reasoning
🏛️ Compliance Framework Alignment
Data lineage and provenance tracking directly supports the following compliance frameworks:
| Requirement | ISO 42001 | SOC 2 Type 2 | ISO 27001 | GDPR | HIPAA | NIST AI RMF | DORA |
|---|---|---|---|---|---|---|---|
| Data origin & source tracking | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Transformation & processing history | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Downstream impact analysis | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| Data consumption & access tracking | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Node ownership & term of use | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| AI data pipeline transparency | ✅ | ✅ |
Why Data Lineage & Provenance Supports Each Framework
🤖 ISO 42001 — AI Management System
ISO 42001 requires organizations to document and trace the data used in AI systems, including its origin, transformations, and intended use. ARPIA's Lineage tab provides a visual, interactive map of exactly how data flows from source tables through Reasoning Flow objects into AI-consumed Knowledge Nodes — satisfying the standard's requirements for AI data transparency, traceability, and accountability across the full data lifecycle.
🔐 SOC 2 Type 2 — Security, Availability, and Confidentiality
SOC 2 auditors require evidence that data processing is consistent, traceable, and controlled over time. ARPIA's lineage graph documents the complete chain of custody for each Knowledge Node — from source repository through transformation steps to consuming applications — providing auditors with the processing integrity evidence required under the Processing Integrity trust service criteria.
🛡️ ISO 27001 — Information Security Management
ISO 27001 requires organizations to understand and document information flows to manage risk effectively. ARPIA's lineage capabilities map every data relationship and dependency across the platform, enabling organizations to conduct accurate impact assessments before making infrastructure changes and to maintain an up-to-date picture of how information assets are connected and consumed.
🇪🇺 GDPR — General Data Protection Regulation
GDPR Article 30 requires organizations to maintain Records of Processing Activities (RoPAs) documenting where personal data comes from, how it is processed, and who is responsible for it. ARPIA's lineage graph — combined with the Knowledge Node Properties fields for Owners, Term of Use, and Knowledge Context — provides the data flow documentation and purpose documentation required to build and maintain accurate RoPAs.
🏥 HIPAA — Health Insurance Portability and Accountability Act
HIPAA requires covered entities to track the flow of PHI through their systems to ensure it is accessed and used only for authorized purposes. ARPIA's lineage visualization shows exactly which tables contain PHI-relevant data, which Reasoning Flow objects process it, and which nodes consume it — enabling organizations to document and audit PHI data flows as required by the Privacy and Security Rules.
🧭 NIST AI RMF — AI Risk Management Framework
The NIST AI RMF's MAP function requires organizations to identify and document the data inputs, transformations, and outputs of AI systems as part of AI risk identification. ARPIA's lineage graph directly fulfills this requirement by providing a real-time, interactive view of AI data pipelines — from source tables through transformation objects to Knowledge Nodes — making AI data dependencies visible and auditable.
⚡ DORA — Digital Operational Resilience Act
DORA requires financial entities to map and document ICT dependencies and data flows supporting critical functions, and to assess the impact of changes or disruptions on downstream processes. ARPIA's lineage graph enables organizations to perform rapid impact analysis across their data ecosystem — identifying which nodes, applications, and AI processes would be affected by a change to any upstream data source — directly supporting DORA's ICT dependency mapping and resilience testing requirements.
Updated 26 days ago